
Generative Engine Optimization for B2B: Why Getting Cited by AI Isn’t the Goal (And What Is)
TL;DR: Generative engine optimization for B2B is the work of getting your company cited inside AI answers from ChatGPT, Perplexity, and Google AI Overviews. Most teams chase those citations as a visibility score. That is the keyword-first mistake on a new surface. The real goal is being the cited answer at the buying decision, which is a decision-first problem, not a tactics problem.
Key Takeaways:
- Generative engine optimization is how a brand earns citations inside AI-generated answers, the way SEO once earned blue-link rankings.
- Getting cited is a visibility score, not a decision. A 2X AI Visibility Index study reported by Demand Gen Report found 96% of B2B companies are invisible in early-stage AI discovery, and most that appear only surface once the buyer already knows their name.
- AI engines are the newest decision surface. The buyer now asks the model who to hire and what to buy, so the citation has to land at the decision, not on a definitional query nobody acts on.
- Decision-first GEO targets being the cited answer at the buying decision. Opollo’s 2026 AI Search Benchmark found AI visitors convert at 14.2% versus 2.8% for organic, because AI referrals arrive closer to the decision.
- The fix is not more citations. It is naming the decision surface first, then building the content cluster to be the answer the engine reaches for at the moment of choice.
Every few weeks another vendor pitches me on getting Grow Predictably cited by ChatGPT. They open a dashboard of brand mentions across AI engines and call it generative engine optimization.
I have watched marketing leaders buy that dashboard, light up at the mention count, and then sit through a quarter where pipeline did not move. The mentions were real. The decisions were happening somewhere the mentions never reached.
This article walks the AI-era marketing leader through what GEO actually is, why treating citation as the goal repeats the original sin of keyword-first content, and how Decision-First Content extends to AI search through a single idea called the decision surface.
This is for the marketing leader who has a GEO vendor in their inbox, a board asking about AI search, and a quiet worry that they are about to spend budget on a number that looks impressive and means nothing.
The work that follows is what decision-first looks like at the AI-search layer: not “get cited more,” but “be the answer the engine reaches for at the moment your buyer decides.”
What is generative engine optimization for B2B?
Generative engine optimization (GEO) is the practice of getting your content cited inside AI-generated answers: the ones ChatGPT, Perplexity, Claude, and Google AI Overviews hand a buyer instead of a page of links.
For B2B teams, GEO is how you show up when a buyer asks an AI engine to recommend a vendor, compare two approaches, or build a shortlist.
GEO sits alongside two related practices you already know:
- Search engine optimization (SEO).
Focuses on earning rankings on traditional results pages so your pages appear in a list of links a buyer can click. - Answer engine optimization (AEO).
Focuses on structuring content so an engine can lift short, direct, self-contained answers: clean headings, concise passages, and extractable blocks. - Generative engine optimization (GEO).
Focuses on influencing whether the model actually names your brand inside its synthesized answer. The on-page mechanics overlap with SEO and AEO, but the real shift is behavioral: the buyer no longer scans ten links and decides; they read one composite answer and the handful of brands the engine chose to include.
Most B2B teams miss that GEO is not just a new traffic channel bolted onto the old funnel. It is a shift in where the buying decision gets shaped. That changes the primary question from “How do we get cited?” to:
- “Cited where in the journey?”
- “Cited at what moment in the decision?”
A mention inside a category explainer and a mention inside the shortlist an engine hands a ready buyer are both citations. Only one of them shapes the decision in a way that leads to revenue, and that distinction is the core of how GEO should be practiced in B2B.
Why getting cited by AI isn’t the goal
Getting cited by AI is a visibility score, not a decision. A brand can be quoted on a definitional query the buyer never acts on, look visible on a dashboard, and still change nothing in the pipeline. Visibility that never reaches a buying decision is the same expensive mistake teams already made with keyword-first content.
The problem shows up clearly when you look at where citations actually land. A 2X AI Visibility Index study reported by Demand Gen Report in April 2026 found that:
- 96% of B2B companies only appear when the buyer already knows their name.
- They are missing from the early discovery questions, where the buyer has a problem but no shortlist yet.
- The result is “visibility” that functions more like a mirror than a magnet: it reflects existing awareness instead of creating new demand.
Rand Fishkin, who left Moz to build SparkToro around exactly this problem, has argued for years that in a zero-click world, traffic is the wrong goal and that what really matters is the moment your brand gets mentioned inside someone else’s interface.
His projection is that the share of searches ending with no click to any website will pass 60 percent, which means the link you used to win is quietly vanishing even as mention counts climb. The mention is the start. Whether it lands at a decision is the whole game.
This is the keyword-first failure wearing a new interface:
- Yesterday: teams ranked for high-volume informational keywords, watched traffic rise, and never saw demos move because the article never joined the buying conversation.
- Today: teams chase mentions on broad definitional queries such as “what is generative engine optimization,” watch AI citation counts climb, and still see no pipeline because those mentions do not happen at a moment of decision.
Even when practitioners admit the problem, they often stop at the metric:
- Some now say AI visibility is a pipeline metric, not a brand metric.
- That is directionally right, but incomplete, because changing the metric does not tell you what content to build or which decisions to serve.
Decision-first content fills that gap by asking a different question first: “Which decision, for which decision-maker, at which moment, on which surface, does this citation need to land in order to matter?”

What is the decision surface, and why does it change GEO?
The decision surface is the place where your buyer actually reaches a buying decision, not just where they learn definitions. For fifteen years that surface was a Google results page and a sales call.
Today, for a growing share of B2B buyers, part of that surface is an AI engine, where the buyer asks the model who they should hire, which approach fits their situation, and what the shortlist should be, and the model answers with names.
You can break the idea down into three key pieces:
What the decision surface is
The decision surface is the context and channel where the buyer finally chooses a vendor, approach, or solution, rather than simply researching.In the past, this was mostly organic search results plus sales conversations; now it increasingly includes AI engines where buyers ask for direct recommendations and shortlists.
How it reframes GEO
The goal of GEO is not to be cited somewhere across the engine, it is to be the cited answer on the surface where the decision gets made. Being quoted in the definition of a category is the AI-era version of ranking for a broad informational keyword: it draws a mention, but it does not enter the room where the choice happens.A category-explainer citation reaches a buyer who is still scoping the problem, while a shortlist citation reaches a buyer who is deciding between named options. Same engine, very different value.
Where relevance engineering fits (and stops)
The most technically serious people in this space already treat AI search as an engineering problem. Mike King, founder of iPullRank and Search Marketer of the Year for 2025, calls the discipline Relevance Engineering.
As he puts it, “we’re not just mechanics tweaking engines, we’re engineers building the actual systems.” His work on passage-level relevance is some of the strongest technical treatment available, and his “raffle ticket” analogy (more coverage, more tickets, more surfaces) is the correct tactic at the technical level.
The limitation is altitude: buying more raffle tickets raises your odds of any citation, it does not, on its own, aim a single one at the decision surface.
This is where decision-first GEO sits one layer above relevance engineering. It tells the engineering which citations are worth winning, the same way Decision-First Content sits one layer above keyword-first SEO and tells you which keywords are worth chasing.
How does decision-first GEO actually work?
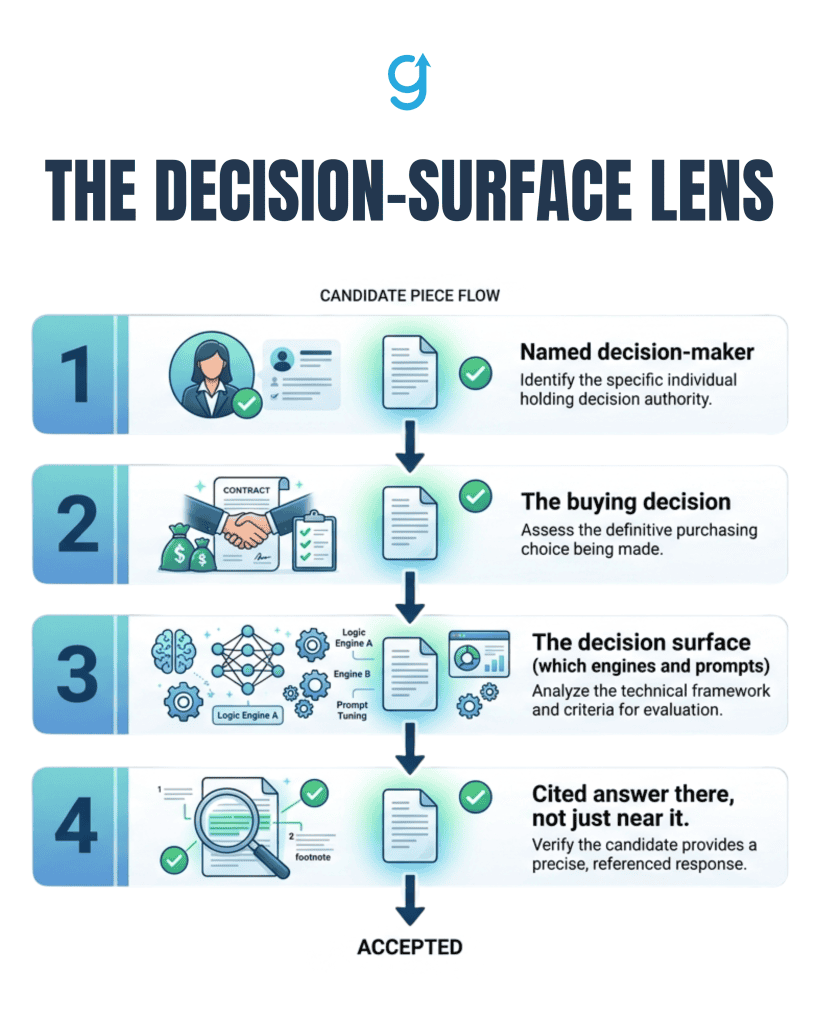
Decision-first GEO works by naming the decision surface before you optimize for any citation, then building a content cluster engineered to be the answer the engine returns at that decision. It is the decision-surface lens from Decision-First Content, applied to AI search, and it runs as a gate you can hold against any candidate piece.
You can break the workflow into clear steps:
1. Start with the decision lens
Before you write or optimize anything, answer four questions:
- Which named decision-maker is this for.
- Which specific buying decision does it serve.
- Where that decision-maker now resolves that decision, including which engines and which prompts they actually use.
- Whether this piece is built to be the cited answer on that surface, not just ranked or mentioned near it.
A piece that could win a citation on a definitional query but not at the decision fails the gate.
2. Aim content at the high-value AI decisions
Benchmarks like Opollo’s 2026 AI Search Benchmark show that AI-referred visitors convert at far higher rates than typical search traffic and that AI may drive a small share of sessions while contributing a disproportionately large share of qualified pipeline.
The takeaway is that the value of AI search is concentrated in a small number of late-stage, decision-oriented queries, not in broad definitional questions. That is why coverage for its own sake becomes a trap.
3. Use the gate to kill low-value citations
In practice, teams often see healthy mention counts across AI engines, but when they inspect the prompts, most of those citations come from definitional or category-explainer questions where the buyer is still scoping the problem.
When you stop chasing breadth, name the 1–2 decision prompts that actually matter, and rebuild a decision pillar plus a few supporting pieces around them, you trade raw coverage for targeted decision-stage citations. Those are the mentions that correlate with buyers opening conversations with lines like “an AI tool suggested we talk to you.”
4. Engineer only the content that belongs on the path to the decision
Decision-first GEO asks you to build only the content a buyer on the path to your chosen decision actually reaches for, and to engineer that content, in the E-E-A-T and AEO sense, to be easy for engines to lift as the cited answer.
The strategy layer (decision-first) tells you which decisions and prompts to target, and the technical layer (AEO, relevance, credibility signals) increases the odds that your answer is the one the engine chooses on that surface.
Thinking about your own funnels, if you picked just one ICP and one decision (for example, “which AI content agency should we hire”), what do you think is the exact late-stage AI prompt that should pass your GEO gate?
What does decision-first GEO look like in practice?
In practice, decision-first GEO means picking one real buying decision, naming the AI prompt your buyer uses to resolve it, and building to be the answer to that prompt. The example below shows the gap between chasing coverage and serving a decision.
The vanity, coverage-first approach
- Chases mentions on broad queries like “what is a content marketing agency” and “types of marketing agencies.”
- Counts total citations across AI engines as success.
- Fails to move pipeline, because nobody hires off a definition.
The decision-first approach
- Starts from one specific decision prompt, for example: “who should run an AI-era content program for a B2B SaaS company, and how do I choose.”
- Builds a decision pillar around that choosing moment, like Hiring a Digital Marketing Agency, with clear criteria an engine can lift.
- Adds only a few supporting pieces (build vs hire, what good looks like, where AI fits) that a buyer actually needs on the way to that decision.
- Ignores definitional citations that look like visibility but never touch the choice.
One decision. One surface. One answer designed to win that prompt. That is the practical shape of a decision-first GEO cluster.
How do you run decision-first GEO in your business?
Run decision-first GEO as a short sequence you can start this quarter, before you sign a GEO vendor or approve a citation dashboard. The output is one decision, its surface, and a small cluster built to win it.
- Name the decision. Pick one real buying decision where you are a legitimate answer. Not a topic, a decision, the one a named buyer is trying to make.
- Name the decision surface. Watch how that buyer resolves it now. Sit with two or three real prospects, or your own buying behavior, and capture the actual prompts they type into ChatGPT, Perplexity, or Google AI mode when they are close to choosing.
- Test your current standing. Type those prompts into the engines yourself and read the answers. See who gets named, what gets cited, and whether you appear at the decision or only on the definition. This is your real baseline, not a mention count.
- Build the decision pillar. Write the one piece engineered to be the cited answer to the decision prompt, with the clean criteria and extractable structure an engine can lift. Anchor it to the decision, the way a diagnostic-first strategy anchors to the one constraint that matters.
- Build only the supporting pieces the buyer asks on the way. Two or three, each resolving a real question on the path to the decision. Skip the definitional coverage that has no path back to a choice.
- Re-test and hold the line. Re-run the prompts monthly. Measure decision-stage citations and the pipeline they touch, not total mentions. When a vendor offers you more coverage, ask which decision it serves. If the answer is none, pass.
Where do you start with GEO that drives pipeline?
Start with one decision and one prompt this week. Open ChatGPT or Perplexity, type the question your buyer asks when they are ready to choose, and read who the engine names. That answer, who gets cited at the decision and whether it is you, is the only GEO metric that predicts pipeline. Everything else is a mention count. Name the decision, name the surface, and build the one answer worth being.
Book a Decision-First Content Diagnostic Call to map your decision surface and the cluster that wins it.

A solid 15 years of Digital Marketing | AI & Automation | SEO & Content Marketing Strategy | Customer Value Journey.
Experience with businesses big & small: Globerunner (SEO & marketing agency), PowerSchool (B2B SaaS), PFSweb (e-commerce), Southwest Airlines (travel), and Mary Kay (beauty & skincare).





